












皮尔森相关和斯皮尔曼等级相关 返回
1.背景
说到相关系数,学过生物统计的人应该不会太陌生。随着基因芯片和高通量测序技术的发展,相关系数在生物数据统计中的应用越来越普遍。例如,通过计算不同基因表达量的相关系数,来构建基因共表达网络。大部分基因网络分析的方法,都与基因间表达量相关系数的计算相关(即使是复杂一点的算法,相关系数的计算也可能是算法的基础部分)。所以理解相关系数,对分析生物学数据非常重要。
2 皮尔森相关
2.1 概念
在所有相关系数的计算方法里面,最常见的就是皮尔森相关。
皮尔森相关百度百科解释:皮尔森相关系数(Pearson correlation coefficient)也称皮尔森积差相关系数(Pearson product-moment correlation coefficient) ,是一种线性相关系数。皮尔森相关系数是用来反映两个变量线性相关程度的统计量。相关系数用r表示,其中n为样本量,分别为两个变量的观测值和均值。r描述的是两个变量间线性相关强弱的程度。r的绝对值越大表明相关性越强。
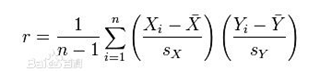
2.2 数据测试
公式是抽象的,我们利用几组值就可以更好理解相关系数的意义。从皮尔森相关系数定义来看,如果两个基因的表达量呈线性关系(数学上,线性相关指的是直线相关,指数、幂函数、正弦函数等曲线相关不属于线性相关),那么两个基因表达量的就有显著的皮尔森相关系性。下面用几组模拟数值来测试一下:
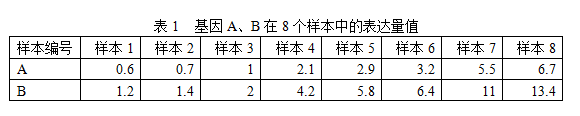
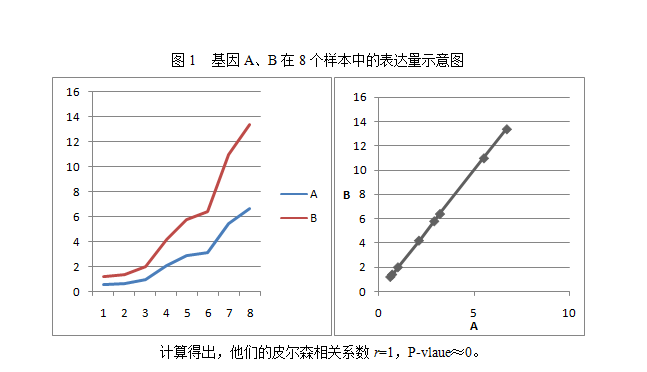
测试1:两个基因A、B,他们的表达量关系是B=2A,在8个样本中的表达量值如下:
测试2:两个基因A、C,他们的关系是C=15-2A,在8个样本中的表达量值如下:
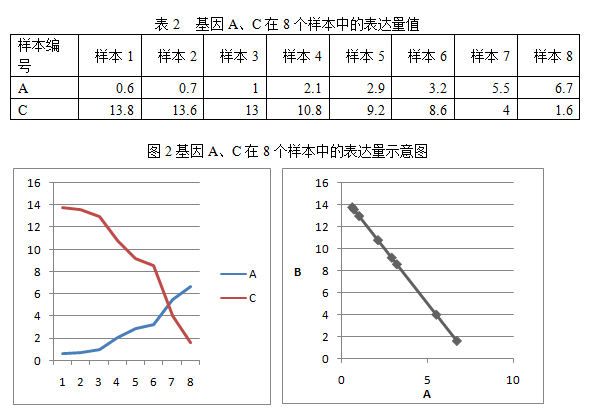
计算得出,他们的皮尔森相关系数r=-1,P-vlaue≈0。
从以上可以直观看出,如果两个基因的表达量呈线性关系,则具有显著的皮尔森相关性。如果两个基因“共舞”(如图1),则两者正相关;如果“你要往东,我偏往西”(如图2),则两者负相关。
以上是两个基因呈线性关系的结果。如果两者呈非线性关系,例如幂函数关系(曲线关系),那又如何呢? 我们再试试。
测试3:两个基因A、D,他们的关系是D=A10,在8个样本中的表达量值如下:
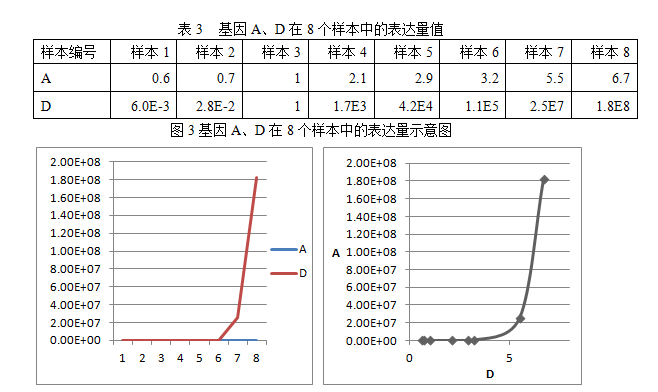
计算得出,他们的皮尔森相关系数等于 0.77,P value= 0.0267。
可以看到,基因A、D相关系数,无论数值还是显著性都下降了。皮尔森相关系数是一种线性相关系数,因此如果两个变量呈线性关系的时候,具有最大的显著性。对于非线性关系(例如A、D的幂函数关系),则其对相关性的检测功效会下降。但在生物体内的许多调控关系,例如转录因子与靶基因、小干扰RNA与靶基因,可能都是非线性关系,那么是否有更合适的相关系数检测方法呢?
其实可以考虑另外一个相关系数计算方法:斯皮尔曼等级相关。
3 斯皮尔曼等级相关
斯皮尔曼等级相关(Spearman’s correlation coefficient for ranked data)主要用于解决称名数据和顺序数据相关的问题。适用于两列变量,而且具有等级线性关系的资料。由英国心理学家、统计学家斯皮尔曼根据积差相关的概念推到而来,一些人把斯皮尔曼等级相关看做积差相关的特殊形式。

简单点说,就是无论两个变量的数据如何变化,符合什么样的分布,我们只关心每个数值在变量内的排列顺序。如果两个变量的对应值,在各组内的排序顺位是相同或类似的,则具有显著的相关性。
举个例子,例如表3的数值,用斯皮尔曼等级相关计算相关系数,将发生如下变化。
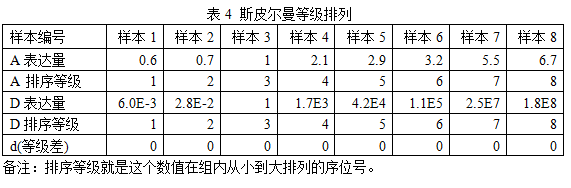
利用斯皮尔曼等级相关计算A、D基因表达量的相关性,结果是:
r=1,p-value = 4.96e-05
这里斯皮尔曼等级相关的显著性显然高于皮尔森相关。这是因为虽然两个基因的表达量是非线性关系,但两个基因表达量在所有样本中的排列顺序是完全相同的,因为具有极显著的斯皮尔曼等级相关性。
4 总结
皮尔森相关和斯皮尔曼等级相关,都是在计算基因共表达或多组学贯穿分析时常用的相关性度量方法。因为基因间调控方式可能并非线性,加上实验误差、检测误差等因素的干扰,皮尔森相关的显著性可能会下降。而斯皮尔曼等级相关可能可以弥补以上的缺陷,因此一些软件也提供了这个选择。例如分析软件TF-cluster默认使用斯皮尔曼等级相关来计算转录因子和基因间的相关性。
但由于生物体调控方式的复杂性,例如多个基因联合调控一个下游基因,我们并不能武断决定哪一种相关性计算方式最佳,还是需要根据具体情况定制个性化的分析策略。
另外,计算两个变量的相关性,可以使用R软件的cor.test命令计算,该命令有pearson, kendall, spearman三种算法供选择。
本文由基迪奥技术部总监编辑。











