












两个样本如何做出好看的热图? 返回
一般我们作热图都会先对数据进行均一化处理,以消除因量纲差异导致的聚类关系失真、数值波动范围过大的影响。
但是当分析的样品只有两个的时候,数据均一化就失去了意义了,为什么?
先看下面的例子:

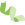
上图就是进行了Z-score均一化后画出来的,只有红色和绿色两种颜色,没有过渡色,非常难看。为什么会这样?
原因就在于,Z-score是一种对数据进行标准化的方法,其计算方法为减去均值除以标准差。公式具体是下面这样的:当你只有两个样本时,每个数据减去均值后必定是一正一负,并且绝对值相等,再除以标准差,这就使得所有样本标准化后的值都只有一正一负两个数值了。所以热图就只能呈现出只有一种红色和一种绿色。
既然数据均一化后只能得到红色跟绿色,那就不均一化,然后就会得到下面这张图。

这张图是用基因的表达量RPKM值来画,大概一看,还觉得比较正常,有颜色渐变。但是再仔细看,你会发现这张图的刻度尺范围比较大,而且绝大部分是绿色?这是什么原因呢?仔细看一下标注你会发现,绝大部分的基因表达量都在10以下,只有两个基因在30以上,所以画出来的热图颜色都往绿色扎堆了。
如果想要画出好看的热图,办法还是有的!
我们建议这时候果断弃掉RPKM值,而选择用两个样品基因表达量的差异倍数来作图。这样就变成单列热图了,可以去除异常高表达基因对整体热图的影响,并且直观展现两个样品之间的基因表达量差异。如下图所示,结果更加清晰:

因此,做热图前对数据进行均一化还是非常有必要的。两个样品画热图,不能进行数据均一化,有时候要根据数据具体情况,用两个样品基因表达量的差异倍数来画热图。
更多基迪奥精彩原创文章,可继续关注我们网站动态发布,同时关注基迪奥微信~扫一扫添加基迪奥好友~随时随地关注行业动态!












