












走近基因组“暗物质” 返回

日前,研究人员取得了一项里程碑式的新成果:他们发现了转录起始的精确位点,从而为解析基因组“暗物质”的起源迈出了重要的一步。这项刊登在《自然》杂志上的研究将有助于分析复杂疾病特征所在的确切位置。
所谓基因组“暗物质”,其实就是基因组中的非编码 RNA ——不包含用于制造蛋白质的版图,构成了超过 95% 的人类基因组。之前的研究认为,非编码 RNA 不编码蛋白质,属于“垃圾”RNA。而随着研究的深入,科学家逐渐发现,非编码 RNA 含有丰富的信息,是生命体中有待探索的“暗物质”。目前已发现很多非编码 RNA 具有的重要生物学功能。同时,越来越多的证据表明,一系列重大疾病的发生发展与非编码 RNA 调控失衡相关。
在这项最新研究中,来自宾州大学分子生物学系的 B. Franklin Pugh 教授,以及博士后研究员 Bryan Venters (目前任职于范德比尔特大学)等人发现了人类基因组中相同类型位置上基本上所有编码和非编码 RNA 起始点,这将有助于查明复杂疾病特征所在的确切位置,因为许多疾病的遗传起始位点位于基因组编码区域以外。
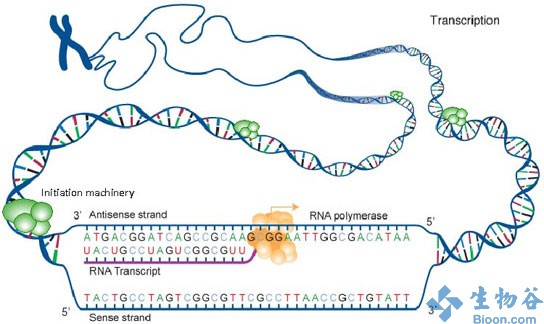
研究人员首先分析转录起始的精确位点,这是基因翻译成蛋白的第一步。“在转录过程中,DNA 通过 RNA 聚合酶,形成 RNA,后者是一种单链遗传物质,科学家们认为 RNA 是地球上出现 DNA 之前的遗传物质。然后通过再经过多个步骤,基因表达成蛋白”,Pugh 解释道。
并且他还补充说,在他们寻找转录起始所在之处的研究期间,其他一些科学家也在直接分析 RNA,但是 Pugh 和 Venters 则是去分析在人类染色体上,启动非编码 RNA 起始转录的蛋白定位在哪里。
“我们之所以采取这种方式,是因为许多 RNA 在制造出来后就立即被降解了,这令我们防不胜防,” Pugh 说,“因此我们没有去寻找转录的 RNA 产物,而是寻找制造 RNA 的‘起始机器’。这种机器组装 RNA 聚合酶,制造 RNA,并最终翻译成蛋白质”。
结果令 Pugh 和 Venters 感到吃惊的是,他们发现了 16 万个这样的“起始机器”,但人类总共也才大约 3 万个基因。
“这一发现十分重要,要知道实际上我们在基因位点处发现的‘起始机器’只有不到 1 万个,而且细胞中大多数基因处于被关闭状态,它们一般都没有用到这些机器。”
对于余下的 15 个起始机器,Pugh 和 Venters 还没有找到它们的归属,这些机器的作用依然待定。“这些与基因没有关联的起始机器显然是活跃的,因为它们能制造 RNA,科学家们也在发现 RNA 片段的同时发现了它们”,Pugh 说,“最开始,这些 RNA 片段由于并不编码蛋白而受到了忽视。”
Pugh 说,很容易就会忽视这些片段,因为它们不具有多聚腺苷酸化polyadenylation的特征(这是指能用于保护 RNA 免受破坏的长串腺苷)。
之后 Pugh 和 Venters 又通过能识别编码基因相关 DNA 序列的非编码起始机器,进一步验证这一研究结果。
“这些非编码 RNA 被称为基因组‘暗物质’,就像是宇宙中的暗物质,难以察觉,没有人知道它们究竟是用来做什么的,或者它们为什么在那里,” Pugh 说,“现在至少我们知道它们是真实的了,不只是‘噪音’或‘垃圾’。当然下一步还需要回答一个问题:‘它们到底是用来做什么的?’”
Pugh 补充说,这项研究的意义在于朝着解决“失踪遗传 missing heritability”这一问题迈进了一大步,这个概念是指大部分特征,包括基因,为何无法通过个体基因进行描述。“当一种疾病的突变图谱指向基因组未知功能区域的时候,很难了解这种疾病的来源”,“不过如果这些区域能制造 RNA,那么我们就能一步步的了解这种疾病。”
文章来自:生物谷











